
Shallow Evals and How to Make Them Right

I am coming back from Trace, Braintrust's flagship event at the California Academy of Sciences in San Francisco. There is a big question I have been sitting with as I work with evals, and the conversations at Trace sharpened it even further. The question is this: WHO is the right persona to pick this up at a company? What will deliver real value to both the users and the engineers? And most importantly, what are the practices and methodologies that are the most critical to do this well?
The closer we are to the real problem statements of the people we are building for, the better we understand what they actually expect from the product. When those expectations get written into evals, something shifts. Teams start writing evals based on assumptions about what users might expect, instead of knowing what the real expectations are. And if the evals guiding the development of the agents are shallow, the entire system builds a false sense of achievement. The evals look great. Whether value has been delivered is a question mark.
When an engineer without context writes evals, we run the risk of working from a blind spot. When a product manager who does not understand the domain they are operating in writes evals, we run the same risk from a different angle. The person writing the eval needs to carry both the technical precision to make the eval measurable and the deep domain understanding to know what is actually worth measuring. That combination is rare, and it is exactly why most eval efforts drift toward shallow.
When evals test the system but not the value
Let me paint a picture. Imagine you are building a chatbot that searches against a database. A user writes a question in natural language, the system classifies it, generates filters, calls Elastic Search, ranks the results, and presents the user with a summary in plain English along with a list of results. Six steps, one final experience for the user.
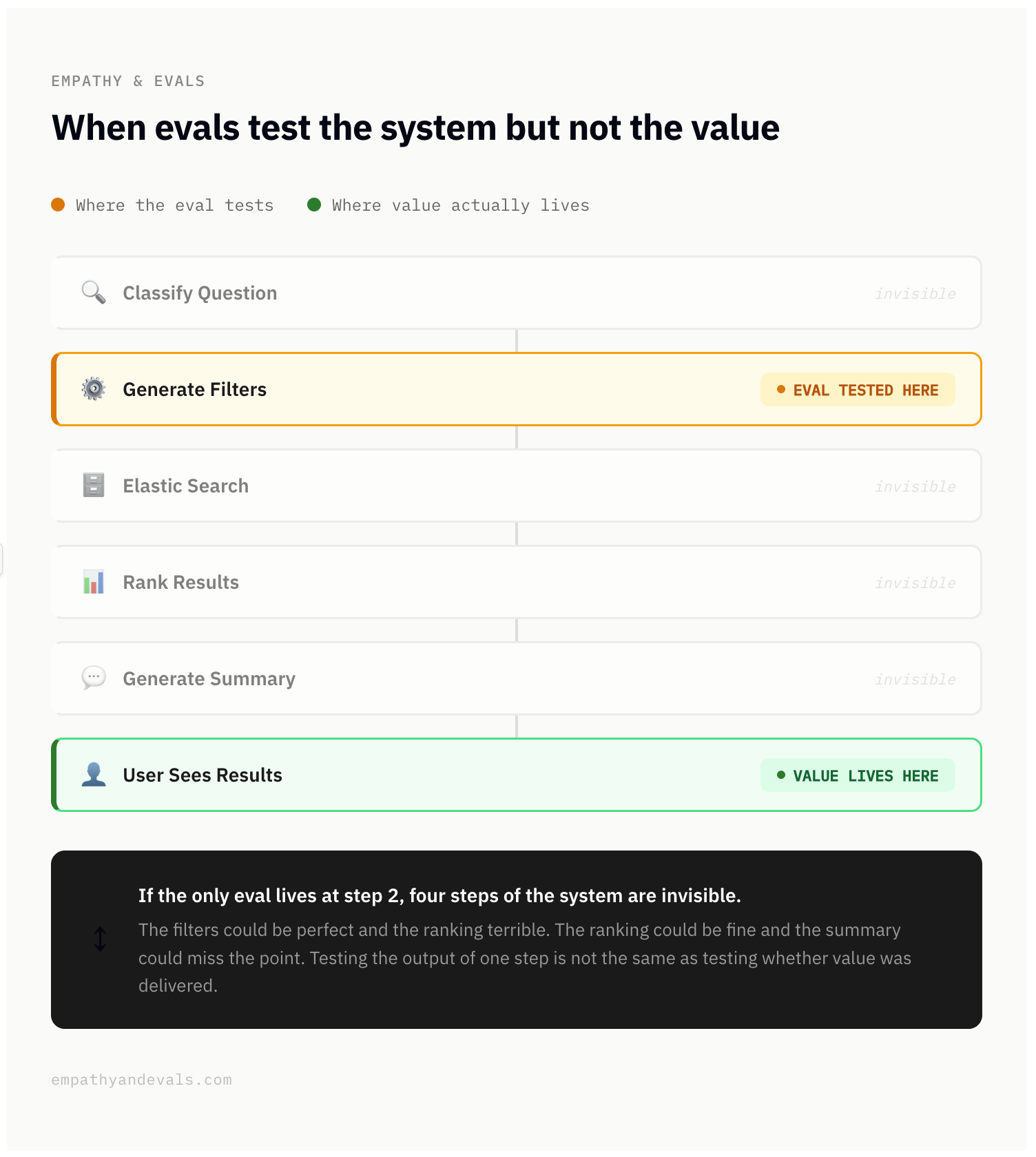
Now imagine the first evals get written. The builders write them, and they write what they know how to measure: whether the filters are being generated correctly. Step two. That is measurable, it is clean, it is something an engineer can say yes or no to. So that is what gets tested.
For a while, those evals look great. The dashboard shows green. There is a feeling of progress.
But what about the other steps? What about how results get ranked? What about the summary? What about whether the person who asked the question actually got a useful answer?
If the only eval lives at step two, all of that is invisible. The filters could be perfect and the ranking terrible. The ranking could be fine and the summary could miss the point entirely. The user could walk away frustrated, and nothing in the eval set would catch it.
Testing the output of one step is not the same as testing whether value was delivered through the entire experience.
The shift that changes everything is when evals start measuring the outcome. When you look at whether the final answer was actually useful to the person who asked the question, you start seeing the system differently. You can trace end to end and see exactly where things break. Sometimes the filters are fine but the ranking fails. Sometimes the ranking is fine but the summary misses the point. You can only see this when you stop testing a step and start testing for value.
What makes an eval deep vs. shallow
A shallow eval checks whether the system produced the right output. A deep eval checks whether value was delivered. The gap between them is where most eval efforts quietly lose their way.
Three dimensions to think about.
The first is source of truth. A shallow eval defines "correct" based on what the builder thinks is right. A deep eval defines it based on what the user experiences as valuable.
The second is what it measures. A shallow eval checks output accuracy: did the agent complete the step? A deep eval checks outcome: did the person get what they needed? There is a world of difference between "the agent returned the correct SQL query" and "the analyst answered the business question they actually had in mind, even though they asked it vaguely."
The third is how it evolves. A shallow eval is static, written once and left to drift. A deep eval is a living artifact that changes as your understanding of the user deepens. This is why continuous product discovery is non-negotiable. If your evals are frozen while your users' expectations keep moving, the gap will only grow.
The eval is not a gate. It is a measure of value.
The role of an eval is not to be a gate that tells you the product is working properly. It is not a unit test for your agent. Yes, write evals that check fundamental things. Whether a step executed correctly, whether the output format is right, whether the system did not break. Those are table stakes. But if that is where your eval effort stops, you are building a system that passes its own tests without ever knowing if it delivered value to anyone.
The goal of an eval is to be a measure of expected value from the system, not a gate that tells you the product is working properly.
The direction needs to be toward value from the start, or you will build a very well-tested system that nobody finds useful.
So what does one actually do about this?
Empathy here is not just a value to hold, it is a skill to practice. It means spending time with users, learning their language, sitting with their frustrations long enough to understand the layers underneath. And then doing the hardest part: translating all of that into specific, measurable expectations that an eval can actually capture. It is not one role. It is a capability that needs to exist somewhere in the system, consistently.
Diagnose the evals you already have. Could this eval pass while the user still fails? Where did the expected outcome come from, a user or a spec? Who wrote it, and did they have deep context on the domain? Is there a feedback loop from real users back into the eval set? If the answers make you uncomfortable, that is the gap between where your evals are and where they need to be.
If you are writing evals for the first time
Here is a checklist. Not a framework, not a philosophy. Just the steps.
- Talk to real users first. Get 12 to 15 interviews set up with end users. Not internal stakeholders, not proxies. If you cannot do this yourself, find someone on your team who asks great questions. Send them. Debrief after.
- Uncover what they expect as an outcome. What is their job to be done? What does "good" look like in their words? Listen long enough to hear what they actually care about.
- Map your evals into layers:
- Unit tests and fundamental system checks. Table stakes. Does each component work in isolation? Write these, but know this is where most teams stop.
- Evals that measure handover from one step to another. Things can go right at step one and fall apart at step three. See whether value is being preserved through the pipeline.
- Evals that measure the outcome based on user expectations. This is where value lives. The hardest eval to write and the most important one.
- Build a ritual to review traces together. Not dashboards. Sit with your team and look at actual traces end to end. Make this regular.
- Create a channel for first-hand user feedback. The signal that tells you whether your evals are aligned with reality.
- Keep the conversations going. User expectations evolve. Your eval set needs to evolve with them.
Some resources worth reading
- Product discovery: Teresa Torres on continuous discovery, and Rob Fitzpatrick's The Mom Test
- Evals: Hamel Husain's writing
- Tooling: Braintrust, whose event started this whole train of thought.
Find people in your team that can bridge the gap between engineering and the consumers, consistently. Whether that is a PM or a designer or a researcher, always keep finding that. And when you sit down to write the eval itself, write it like you are encoding a promise to the person on the other side.
Not a promise that the system works, but a promise that you understood what they needed.