
Opus 4.5, vague inputs and empathy + evals

Let me start by saying, holy shit. I love this.
Opus 4.5 launched, and I had 30 minutes to myself in a cafe while a friend stepped out. I grabbed my iPad, installed Claude, installed Claude on Chrome (which I couldn't quite get working), and just started with Claude on ipad. I asked it what platform to pick for a blog. I didn't want Wix. It told me Ghost, explained what it was, and within that session on my iPad, the basic setup was done.
When I got home, I opened Cowork. I wanted to finalize the visuals, give feedback on how things looked, make sure the blog had all the parts I needed. For context, when I first learned to write code, my Achilles heel was CSS, HTML, all that frontend stuff. I could never figure out how to run the JavaScript file properly. Cut to now. I restarted the visual work at about 9:30 PM. By 10 PM, everything was sorted. All the visual elements in place. Newsletter triggering. The entire workflow started and concluded within Cowork. The website went up, two blogs went live, completely done through Claude.
Once I knew how Ghost worked and how quick this whole thing could be, I turned my attention to my personal website, rishigb.me, which I've been struggling with for months. It's built on Wix and it has all the problems you'd expect. Pages take forever to load on mobile. Animations I can't turn off. A comment section that's painful to use. A "Get in Touch" button that's broken. No easy way to do subscriptions or newsletter delivery without buying more tools.
So I asked Claude to recreate the entire site on a new Ghost template. Coded exactly as it is, including fonts, including everything. I started a new project while my first one was still running. In the background, it picked up every single element of my existing website. I gave it access to a fresh Ghost instance and said: pick the most basic template, decide whether it makes sense to edit a template or build from scratch, and start. Within 15 minutes, all the configuration settings, the navigation menu, all of it was understood, and it had started creating pages and setting up navigation right in front of me.
And that's when it hit me.
There's a specific thing that happened during this process that I keep coming back to. I told Cowork things like "this part of the screen looks off, there are gaps in spacing" and "does this text look too big?" and "this highlight looks strange." These were vague inputs. They were based on my intuition, on something feeling wrong without me being able to articulate exactly what was wrong. And it figured out exactly what needed to be done.
It doesn't need to be specific anymore.
This reminded me of something. Back in 2017, I was working with a designer. A talented one. But it took us a full six months of working together before she truly understood my taste. Six months of me saying "this doesn't feel right" and her asking "what do you mean?" and us slowly, painfully calibrating to each other. By the end of those six months, she could anticipate what I wanted. She'd make changes before I asked, because she had built a mental model of my preferences through hundreds of small interactions.Opus did that the first time we met.
Something about that is both crazy and strange. A human designer, someone brilliant at her craft, needed six months of shared context to reach that level of understanding. And here was a model that picked up on "this highlight looks strange" and translated it into the exact right fix, on the first conversation. Not because it knows me, but because it's gotten remarkably good at modeling what a human might mean when they express something vaguely.
I spend a lot of my working hours thinking about evals, about how we measure whether AI systems actually understand what they're being asked. And what struck me about this experience is that the hardest thing to evaluate is not whether a model can follow a precise instruction. That's relatively straightforward to test. The hard thing is whether a model can interpret what someone means when they can't fully express it themselves. When the input is a feeling, not a specification.
This is empathy in the truest sense. Not emotional empathy, but cognitive empathy. The ability to model someone else's mental state, to fill in the gaps between what they said and what they actually wanted. And from what I experienced, Opus 4.5 is getting surprisingly good at that.
Most eval frameworks test against ground truth: did the model produce the correct output for a given input? But when the input itself is ambiguous, when the "correct" output depends on understanding the human behind the request, our eval frameworks start to break down. We can test whether a model follows instructions. We don't yet have good ways to test whether a model understands intent. I think this is the next frontier for evals. Not "did you do what I asked?" but "did you understand what I was trying to ask?" The gap between those two questions is where empathy lives.
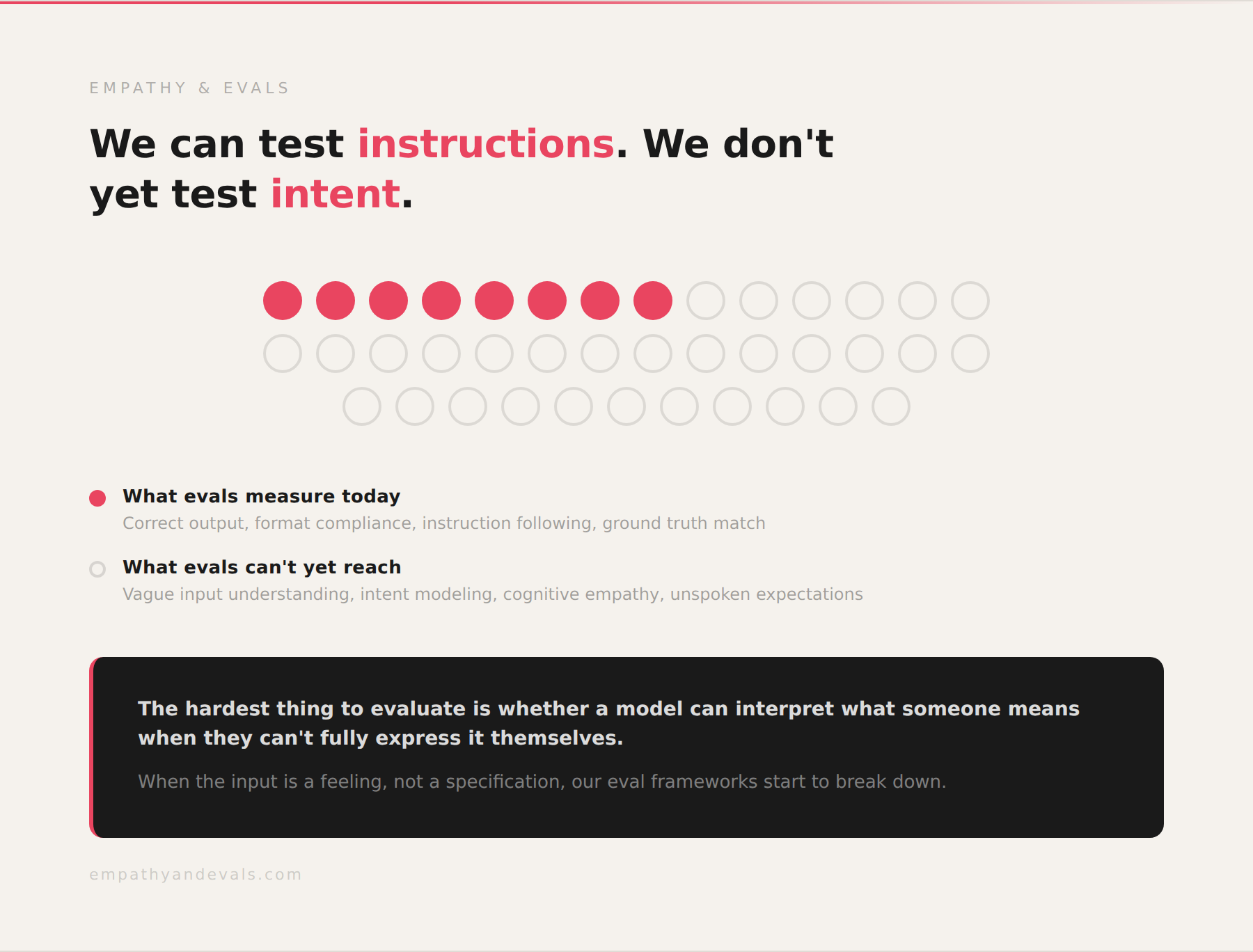
And that brings me to what excites me most. If it understood my vague aesthetic preferences on day one, something that took a human collaborator six months, how do we design expectations and tastes from humans into AI products more broadly? How do we build systems that don't just respond to what you say, but understand what you mean? And how do we measure whether they're actually getting it right? These are the questions I'm now obsessed with.
What impressed me
- Cafe to live website in one evening. I went from zero to a fully functional Ghost blog with newsletters, visuals, and two published posts in under an hour. The entire thing was done through Cowork and Claude, starting on an iPad and finishing on my Mac.
- Full website migration without hand-holding. I pointed it at my existing Wix site and a blank Ghost instance and said "recreate this." It picked up every element, fonts, layout, navigation, and started building autonomously. Within 15 minutes, configuration and page creation were underway.
- Vague feedback actually worked. "This spacing looks off." "This text looks too big." "This highlight is strange." I gave it intuition-based, imprecise inputs, and it consistently made the right fixes. No follow-up questions, no clarification needed. This was the most striking thing.
- Three intense parallel tasks. It handled blog setup, visual refinement, and a full site migration across overlapping projects without losing the thread of any of them.
- Best reasoning and instruction-following I've seen. When I tried similar tasks with Haiku, it struggled to understand the full scope. Opus held the complexity without breaking.
- The trajectory is wild. I can see a near future where you sit for an hour, jot down your thoughts, create a skill that launches Cowork for an entirely new business: SEO-friendly, self-hosted, with all the UI, content, backlinks, and responsive design handled. Work that would normally need several people, done on a $100/month plan.
Where it struggled
- Same-domain tab confusion. Because Cowork works through Chrome and I had two Ghost sites open (same domain, different instances), it got confused about which site to edit. The intelligence goes deep, but spatial context across tabs is still a weak point.
- No parallel workspaces. I wanted to run multiple deep tasks across my screens simultaneously, each in its own workspace. That's not possible yet, and for a multi-screen setup it's a real limitation.
- Lost conversation history on re-login. When I logged out and back in, some of my conversation threads disappeared. Minor for now, but worth noting for something freshly launched.
- Single-model ceiling. Claude does some things incredibly well, but there are edges where it doesn't. Being locked into one model means you can't stress-test or compare approaches across different models within the same workflow.
And the real question I'm sitting with now is this: if it can understand my vague aesthetic preferences for a blog, can it understand the context of a codebase at work? Can I point it at a bug that's been bothering me and let it figure out not just the fix but why the bug exists in the first place? Can I clone one of our internal products and have it suggest improvements, because I have the ideas and I know where things are breaking?
These are the questions that connect back to empathy and evals. Because what I'm really asking is: how far does this understanding go? At what point does "it figured out what I meant" stop working? Finding that boundary, mapping it, measuring it, that's the eval work that matters most right now.
And from what I saw that evening, that boundary is further out than I expected.